REDO와 UNDO
REDO와 UNDO의 중요성
트랜잭션이 가지고 있어야 하는 특성에 'ACID'라는 것이 있습니다. 이 특성을 구현하기 위해서 REDO와 UNDO는 빠질 수 없으므로 이들을 배울 필요가 있습니다.
A(Atomicity): 원자성
트랜잭션에 포함된 데이터의 변경은 '전부 OK'이거나 '모두 NG'라는 'all or nothing'을 말합니다. DBMS는 수행 중인 트랜잭션에서 데이터를 일부만 변경하고 나머지는 수행하지 않은 채 commit 할 수 없습니다. e.g, 어떤 트랜잭션에서 A 계좌에서 출금하고 B 계좌에 입금했을 때 출금은 기록됐지만 입금은 기록되지 않은 상황이 발생하면 곤란합니다. 원자성은 이러한 일이 일어나지 않도록 보장하는 것이고 트랜잭션은 더 이상 분리할 수 없는 데이터 변경을 위한 최소 단위입니다.
C(Consistency): 일관성
트랜잭션에 의해 데이터 간의 일관성이 어긋나서는 안 된다는 의미입니다. e.g, 고객 개인의 데이터는 변경되었는데, 고객 전체의 통계 데이터는 변경되지 않은 경우
I(Isolation): 고립성
트랜잭션끼리는 고립(분리)되고 독립되어 있다는 것을 말합니다. 어떤 트랜잭션을 단독으로 실행했거나 다른 트랜잭션과 동시에 실행했더라도 결과는 같아야하며 다른 트랜잭션을 의식하지 않는 것을 의미합니다. 단 DBMS에 따라 어느 정도 고립시킬 것인가에 대한 레벨을 선택할 수 있습니다.
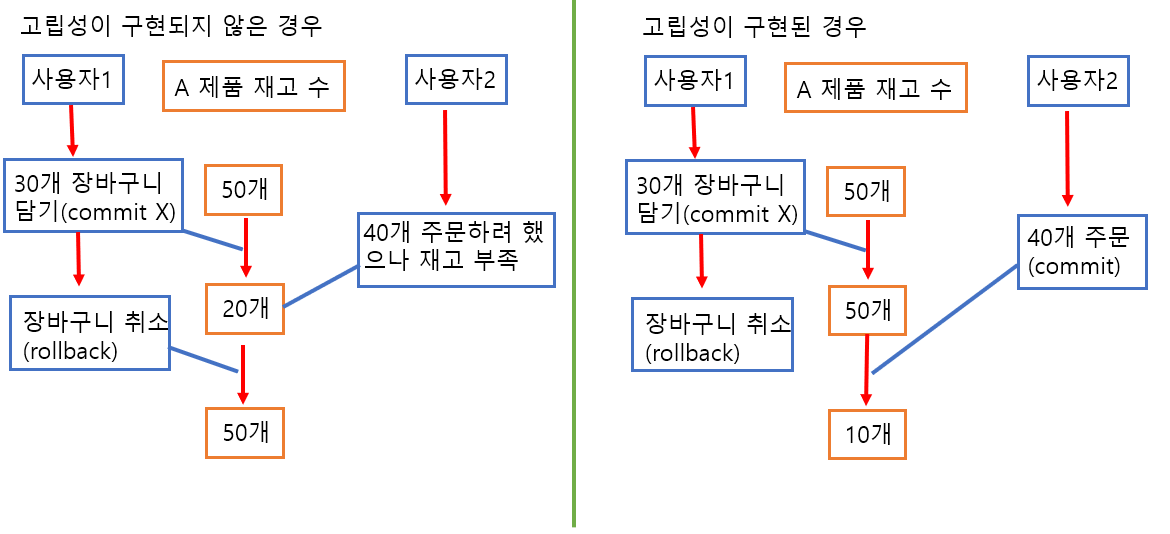
D(Durability): 지속성
커밋한 트랜잭션은 장애가 발생하더라도 데이터는 반드시 복구되어야 한다는 의미입니다.
ACID 요약
- 트랜잭션 단위로 변경(또는 롤백)되어야 한다.
- 어중간한 데이터 변경은 안 된다.
- 다른 트랜잭션과 동시에 실행하든 단독으로 실행하든 결과는 같아야 한다.
- 장비가 꺼지더라도 커밋한 데이터는 복구할 수 있어야 한다
지속성 구현
Durabiliy 커밋한 데이터를 지키는 특성(지속성)을 구현하기 위해서 커밋한 데이터를 즉시 디스크에 기록할 경우 데이터가 클 때 시간이 너무 많이 걸릴 수 있습니다.

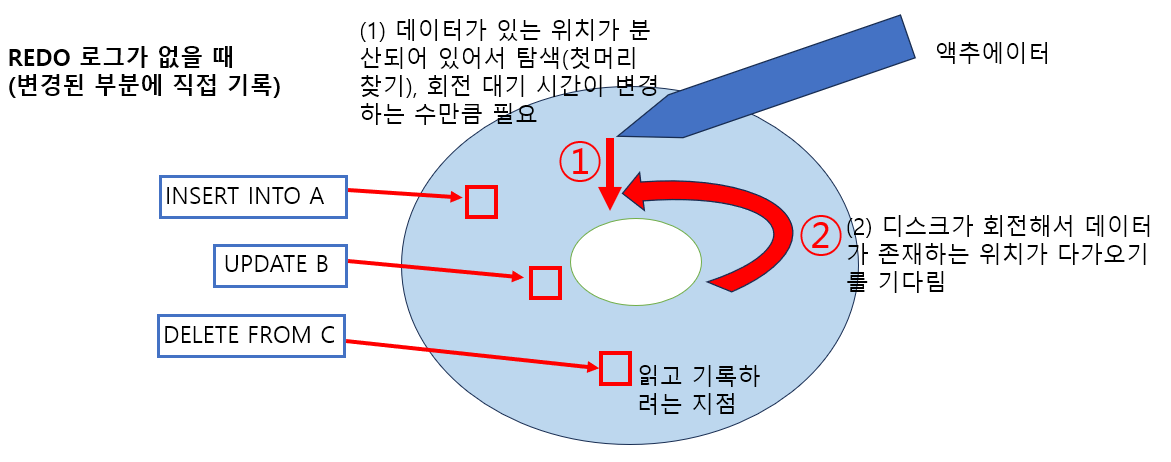
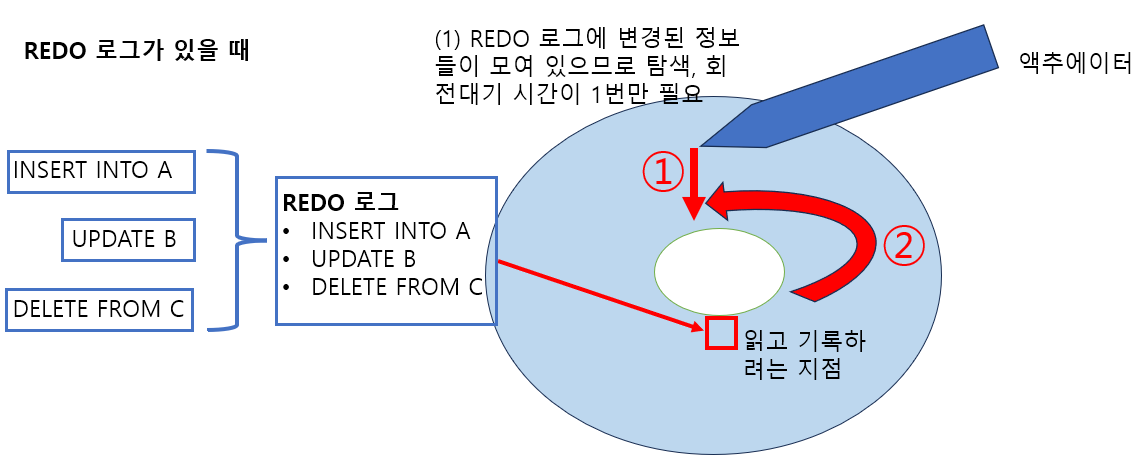
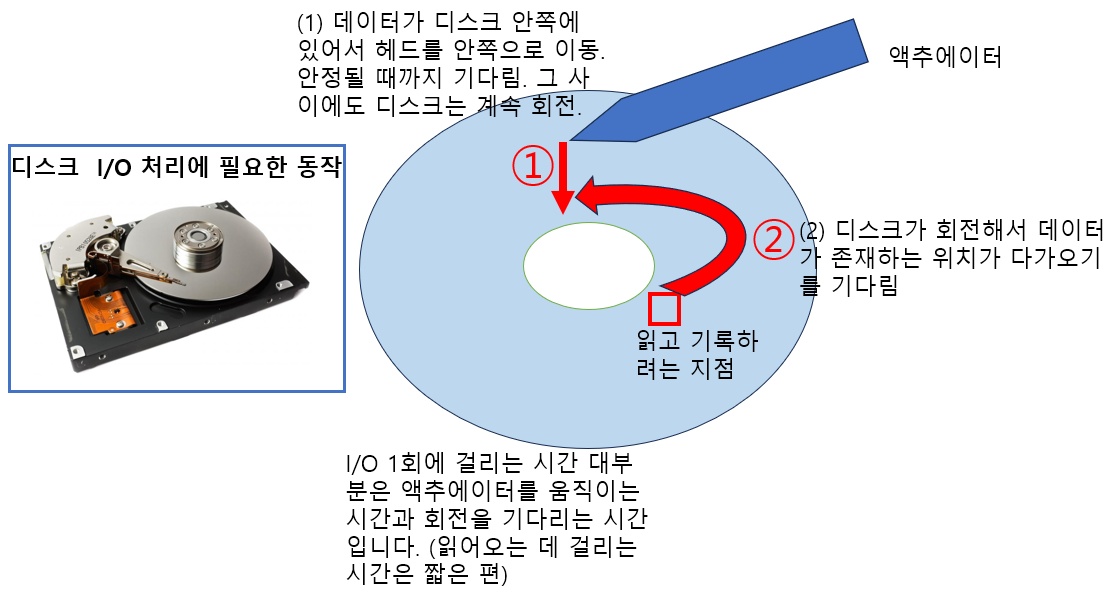 이러한 문제를 해결하기 위해 REDO 로그를 활용해서 데이터를 한꺼번에 기록함으로써 I/O 횟수를 줄이고 시퀀셜 액세스를 사용하여 I/O에 소모되는 시간을 줄였습니다.
이러한 문제를 해결하기 위해 REDO 로그를 활용해서 데이터를 한꺼번에 기록함으로써 I/O 횟수를 줄이고 시퀀셜 액세스를 사용하여 I/O에 소모되는 시간을 줄였습니다.
REDO와 UNDO의 개념
가상 세계에서는 필요에 따라 시간을 되돌릴 수 있습니다. 또한 가상 세계 안에 문제가 발생하여 정보가 손상되면 가상 세계를 다시 과거로 돌려야 하는 경우도 있습니다. 과거로 다시 돌리기 위해서는 가상 세계가 유실되었을 때 최신 상태까지 복구하기 위한 정보가 필요합니다. 어떤 시점의 가상 세계 정보 + 가상 세계의 변경 정보(누가 무엇을 했다)가 있다면 최신 상태까지 복구할 수 있을 것입니다. '누가 무엇을 했는지'에 대한 변경 정보만으로는 현재 상태에서 과거로 상태로 시간을 되돌릴 수 없습니다. e.g, 'A군이 오늘 학교에 갔다'의 경우 A군이 학교에 가기 전에 어디에 있었는 지 알 수 없으므로 학교에 가기 전의 시간으로 되돌릴 수 없습니다. 이를 해결하기 위해서는 '어떻게 해야 과거의 상태로 되돌아갈 수 있는가'라는 정보도 필요합니다.
이 가상 세계를 데이터베이스로 볼 때 '누군가 무엇을 했다는 정보'가 REDO 로그, '어떻게 하면 과거의 상태로 돌아갈 수 있는지에 관한 정보'가 UNDO 정보입니다. REDO 로그를 사용해서 과거의 데이터를 최신 데이터 쪽으로 흐르게 하는 것을 '롤 포워드(roll-forward)'라고 합니다. 반대로 UNDO의 정보를 사용해서 변경을 취소(과거의 상태로 되돌리는 것)하는 것을 '롤백(rollback)'이라고 합니다. Oracle의 SCN(System Change Number)의 경우 가상 세계의 시간에 해당합니다. Oracle 내부의 시간(정확히는 시간이 아닌 번호)를 나타내며 복구 등에 사용됩니다.
REDO의 구조
데이터의 변경은 캐시에서 이루어지는데 이때 REDO 로그(변경 이력 데이터) 데이터가 생성됩니다. Oracle의 경우 REDO 로그를 커밋이 발생하기 전에 디스크에 기록하는 방식으로 지속성을 구현했습니다.
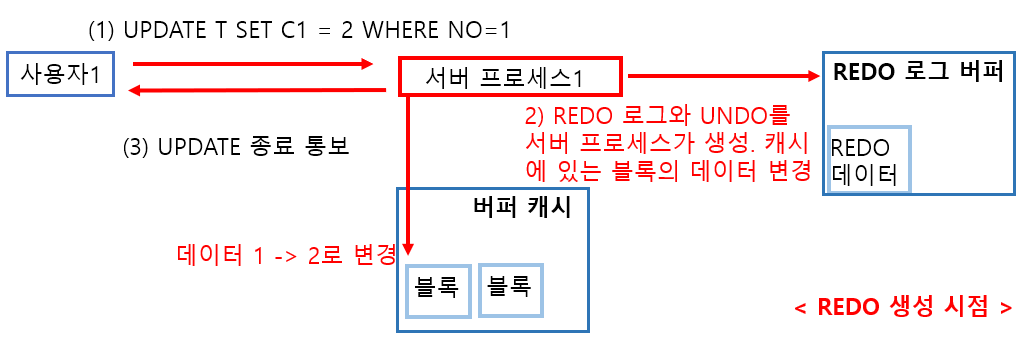
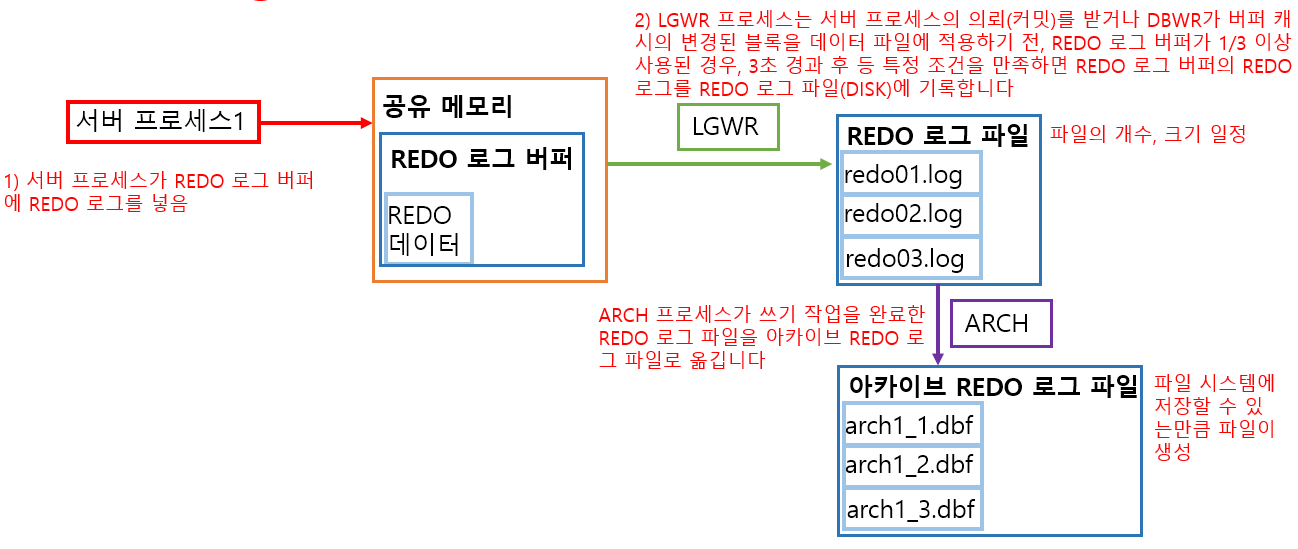
REDO 로그의 구조는 REDO 로그용 메모리로서 REDO 로그 버퍼가 공유 메모리에 존재합니다. REDO 로그를 디스크에 REDO 로그 파일로 기록하는 작업은 LGWR라는 프로세스가 수행합니다. 또한 REDO 로그 파일은 개수가 한정되어 있으며 크기도 제한이 있어서 계속 보관할 수는 없습니다. (기본적으로 로그 그룹 3개) 그래서 오랫동안 REDO 로그를 보관하기 위해 아카이브 REDO 로그 파일이 존재합니다. REDO 로그 파일은 REDO 로그의 일시적인 보관 창고이고 아카이브 REDO 로그 파일이 오랫동안 보관할 수 있는 창고입니다. 데이터베이스의 백업을 받을 경우 백업 시점 이전에 만들어진 아카이브 REDO 로그는 필요하지 않습니다.
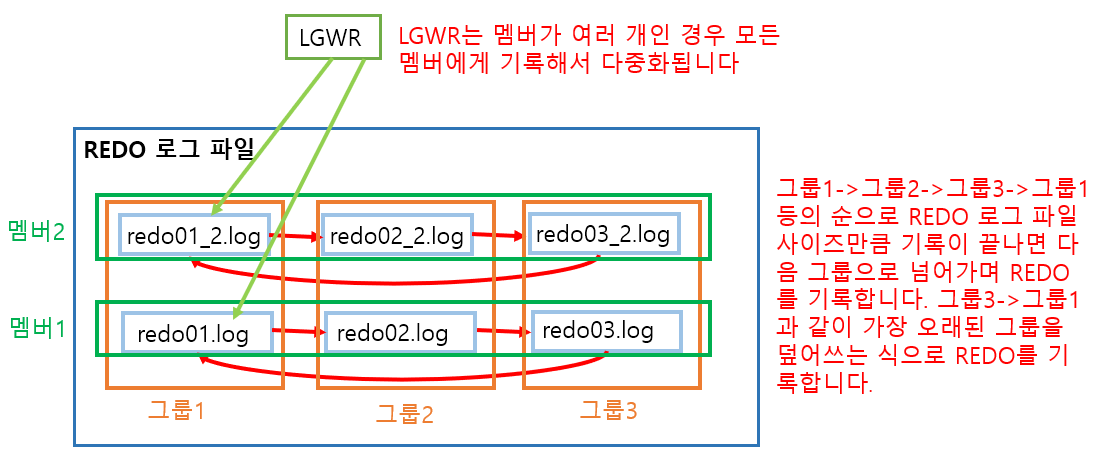
REDO 로그 파일은 문제 발생 상황에 대비하여 다중화가 필요합니다. 일반적으로 REDO 로그 그룹이 여러 개가 존재하고 각 그룹 안에 멤버(REDO 로그 파일)를 추가합니다. 기본적으로 REDO 로그 그룹은 3개 정도 있고 각 그룹당 멤버는 1개씩 존재하는데 다중화를 할 경우 각 그룹안의 멤버(REDO의 복사본을 저장)를 추가하는 방식으로 다중화가 이루어집니다.
서버 프로세스는 commit 시 LGWR 프로세스에게 REDO 로그를 기록하도록 요청합니다. 요청을 받은 LGWR 프로세스는 REDO 로그를 REDO 로그 파일에 기록한 뒤 서버 프로세스에게 기록이 끝났다고 응답합니다. 그후 서버 프로세스는 commit 완료된 것을 클라이언트에게 응답합니다. Statspack(또는 AWR)이나 v$session_wait 등에서 자주 볼 수 있는 'log file sync'라는 대기 이벤트는 주로 LGWR가 REDO 로그를 기록하는 것을 기다리는 것입니다. Oracle의 경우 commit 전 데이터, commit 후 데이터 모두 REDO에 기록하기 때문에 항상 발생하는데 커밋 횟수를 줄이거나 write 캐시를 가진 스토리지(Oracle의 write는 디스크에 기록되기 전까지 끝나지 않지만 write 캐시가 있을 경우 write 캐시에 기록하는 것으로 끝남)를 사용할 경우 조금 더 시간을 줄일 수 있습니다. 또한 REDO 로그에 관련한 처리 과정들은 Latch 보호하고 있으며 Statspack(또는 AWR)에서 'redo copy', 'redo allocation' 등으로 표시되는 Latch가 REDO 로그를 위한 Latch입니다.
REDO 요약
병렬 처리를 가능케 하고 높은 처리량을 실현
여러 서버 프로세스가 동시에 데이터를 변경할 수 있으며 (같은 데이터 제외), REDO 로그를 기록할 때도 LGWR는 여러 서버 프로세스의 REDO 로그를 한꺼번에 기록하기 때문에 높은 처리량을 구현할 수 있습니다.
응답 시간(response time) 중시
commit 시 블록을 REDO 로그에 기록한 뒤 응답함으로써 빠르게 commit을 완료합니다.
commit한 데이터 보존
장애가 생겨서 DBWR가 데이터를 기록할 틈이 없었어도 REDO 로그와 데이터 파일에 남아있는 데이터를 활용해서 데이터를 복구(롤 포워드)할 수 있습니다.
UNDO의 구조
what? UNDO는 예전의 데이터로 되돌리기위한 데이터로 롤백 세그먼트라고도 합니다.
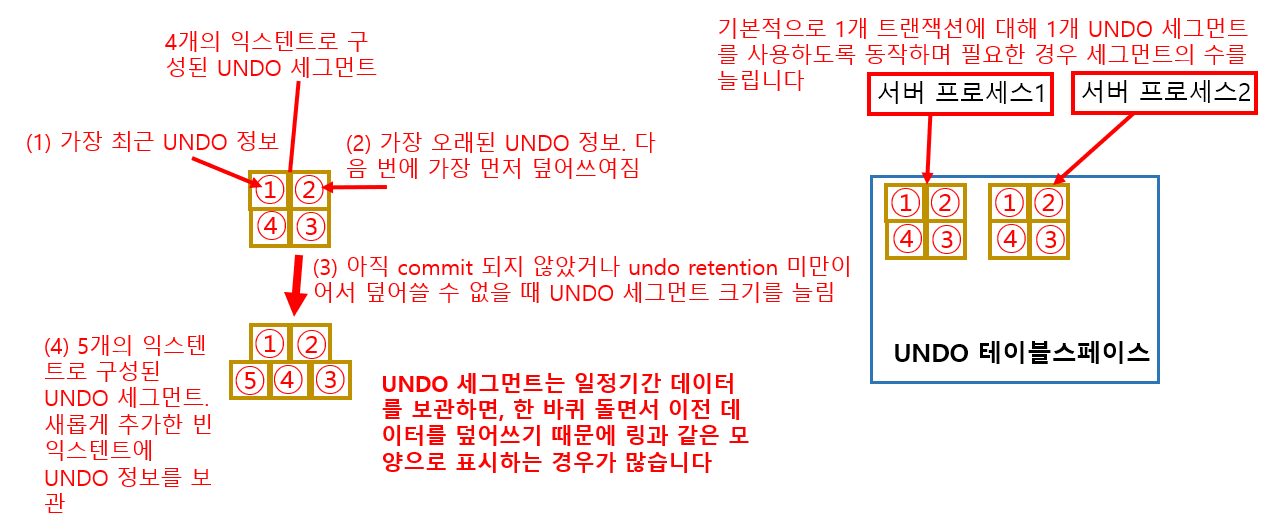
데이터가 변경되면 UNDO 정보를 생성하고 세그먼트에 보관합니다. UNDO 정보가 보관되는 테이블스페이스를 UNDO 테이블스페이스라고 합니다. UNDO 테이블스페이스에는 여러 개의 UNDO 세그먼트가 생성됩니다. 기본적으로 트랜잭션과 UNDO 세그먼트가 일대일로 대응하기 때문입니다. UNDO 세그먼트는 ring buffer로 조금 지나면 데이터가 덮어쓰이는 버퍼지만 commit하지 않은 데이터는 덮어써지지 않습니다. 덮어쓰지 못하고 UNDO 세그먼트가 가득 차면 UNDO 세그먼트가 커집니다.
undo_retention이라는 파라미터 등으로 UNDO 정보의 유지 시간을 설정 가능합니다. UNDO 정보를 commit한 이후에도 일정 시간 유지하는 것이 필요할 때 사용할 수 있습니다.
여러 상황에서 REDO와 UNDO의 동작
ROLLBACK할 때의 동작
Oracle에서는 COMMIT하지 않았더라도 데이터베이스의 데이터는 이미 변경된 상태입니다. ROLLBACK이 수행된다면 UNDO에 보관된 정보를 사용해서 데이터를 원래의 값으로 되돌립니다. 서버 프로세스가 비정상적으로 종료된 경우에도 PMON이라고 불리는 백그라운드 프로세스가 정기적으로 체크를 수행하며 종료된 서버 프로세스를 정리합니다. 또한 SMON이라고 불리는 백그라운드 프로세스가 데이터를 트랜잭션 시작 전의 상태로 되돌려줍니다.
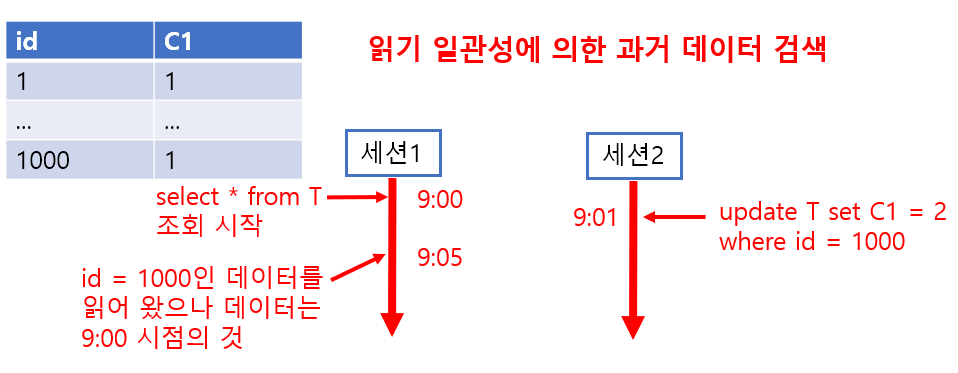
읽기 일관성에 동반되는 동작
what? 읽기 일관성은 데이터를 검색할 때 어떤 시점의 데이터를 보여주는 기능을 의미합니다.
e.g, 검색을 시작한 후 다른 세션에서 변경한 데이터를 (COMMIT한 경우도) 읽지 못지 못하게 하고 검색 중에는 계속 검색을 시작한 시점의 데이터를 보여주는 경우.
how? 읽기 일관성을 위해 UNDO를 사용합니다. 읽기 일관성은 데이터가 변경된 시점을 확인하고 검색을 시작한 후 변경된 데이터일 때는 UNDO를 사용해서 과거의 데이터를 메모리 위에 재현합니다.
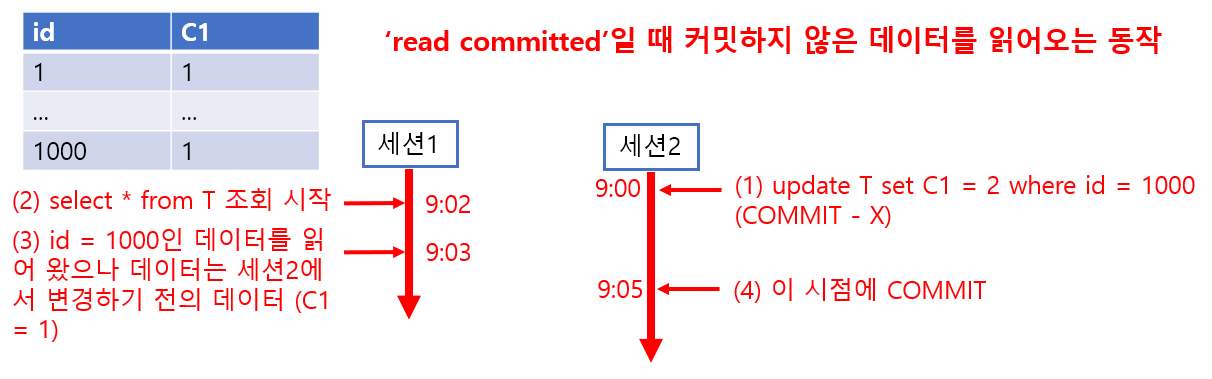
COMMIT되지 않은 데이터를 읽어올 때의 동작
Oracle에서는 기본적으로 고립성(isolation)을 지키기 위해 'read committed'라는 동작을 하도록 설정되어 있습니다. 이는 '다른 세션에서 COMMIT한 변경 데이터는 읽을 수 있다'는 특징을 가지고 있습니다. 그러나 다른 세션에서 COMMIT되지 않은 변경 데이터는 읽어올 수 없습니다. COMMIT되지 않은 다른 세션의 데이터를 읽어올 때도 읽기 일관성과 마찬가지로 변경 전 데이터를 보여주며 필요한 경우 UNDO를 사용해 과거의 데이터를 메모리 위에 재현하는 방식으로 구현합니다.
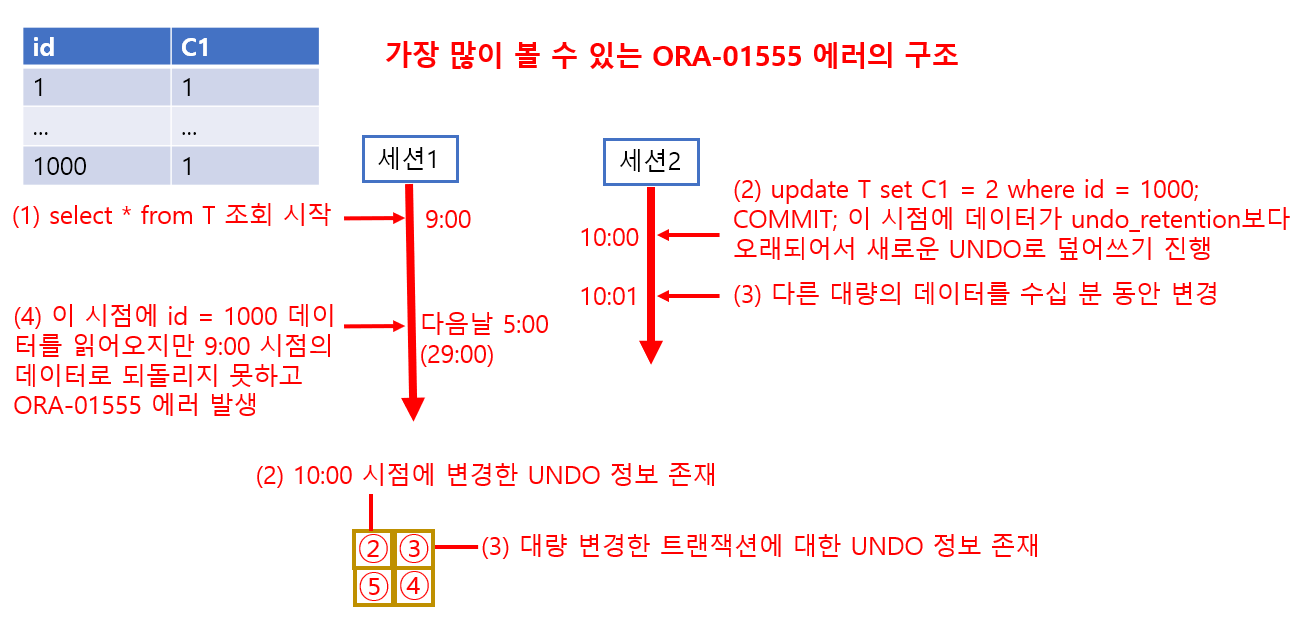
ORA-01555 Snapshot too old 에러가 발생했을 때의 동작
what? 과거의 데이터를 보려 했으나 필요한 정보가 없어진 경우를 의미합니다.
why? 대부분 시간이 오래 걸리는 검색을 수행할 때 UNDO의 정보가 덮어써진 것이 원인입니다.
e.g, 24시간 걸리는 검색을 시작하고서 1시간 뒤 다른 세션이 어떤 데이터를 변경하고 COMMIT 했는데 몇 시간 후 해당 데이터에 관한 UNDO 정보가 덮어써서 사라진 경우.
검색을 시작하고 20시간이 지난 후 데이터가 변경된 부분을 읽기 시작했을 때 Oracle은 데이터가 변경되었으므로 검색을 시작했을 때의 데이터를 재현하려고 합니다. 하지만 UNDO 정보가 없어져 필요한 데이터를 재현해서 가져올 수 없으므로 ORA-1555(snapshot too old) 에러가 발생하며 검색에 실패합니다.
 에러가 발생하지 않도록 하려면 UNDO 정보를 더 길게 유지하도록 설정해야 합니다. undo_retention 파라미터를 사용해서 UNDO 보존 기간의 하한값을 지정할 수 있지만 이 파라미터는 UNDO 테이블스페이스의 자동 확장 기능(autoextend)이 ON으로 되어 있을 때만 유효합니다. 따라서 undo_retention을 설정하려면 UNDO 테이블스페이스의 자동 확장 기능을 ON으로 변경하고 필요에 따라 MAXSIZE 값을 설정할 수도 있습니다. 또한 UNDO 테이블스페이스가 부족할 경우 undo_retention에서 지정한 시간보다 적더라도 UNDO 정보가 삭제됩니다. 따라서 v$undostat 정보를 토대로 UNDO가 10분 동안 얼마나 생성됐는지를 파악한 후 undo_retention을 크게 했을 경우 UNDO 테이블스페이스가 감당할 수 있는지를 검토하고 값을 변경해야 합니다.
에러가 발생하지 않도록 하려면 UNDO 정보를 더 길게 유지하도록 설정해야 합니다. undo_retention 파라미터를 사용해서 UNDO 보존 기간의 하한값을 지정할 수 있지만 이 파라미터는 UNDO 테이블스페이스의 자동 확장 기능(autoextend)이 ON으로 되어 있을 때만 유효합니다. 따라서 undo_retention을 설정하려면 UNDO 테이블스페이스의 자동 확장 기능을 ON으로 변경하고 필요에 따라 MAXSIZE 값을 설정할 수도 있습니다. 또한 UNDO 테이블스페이스가 부족할 경우 undo_retention에서 지정한 시간보다 적더라도 UNDO 정보가 삭제됩니다. 따라서 v$undostat 정보를 토대로 UNDO가 10분 동안 얼마나 생성됐는지를 파악한 후 undo_retention을 크게 했을 경우 UNDO 테이블스페이스가 감당할 수 있는지를 검토하고 값을 변경해야 합니다.
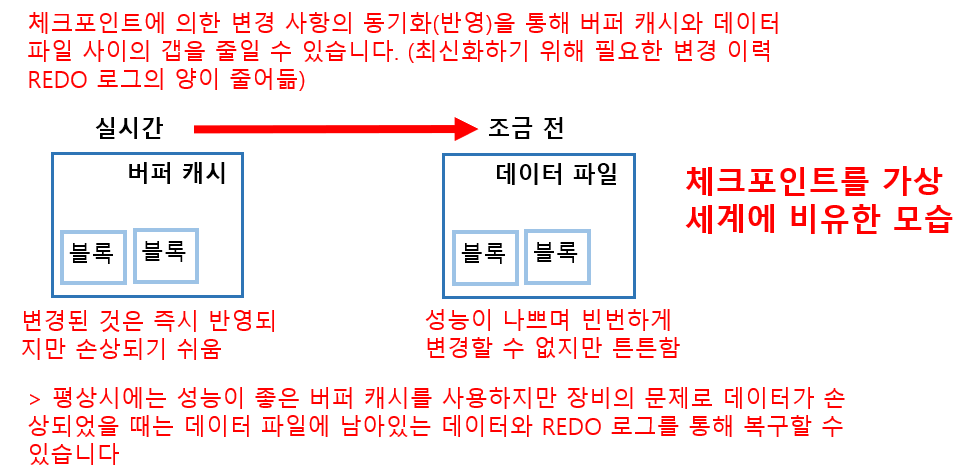
체크포인트의 동작
what? 체크포인트는 메모리의 데이터를 디스크와 동기화하는 작업을 말합니다. DBWR가 데이터를 메모리에서 디스크로 기록합니다.
why? REDO 로그와 예전 데이터가 있다면 롤 포워드는 할 수 있지만 너무 오래된 데이터를 기점으로 롤 포워드하려면 많은 시간이 필요합니다. 체크포인트를 통해 데이터를 정기적으로 디스크에 기록함으로써 롤 포워드에 걸리는 시간을 단축시킬 수 있습니다. 체크포인트는 파라미터를 통해 제어할 수 있지만 디스크에 빈번하게 기록하면 병목 현상이 발생해서 성능을 저하시킬 수 있으므로 너무 빈번하게 기록하지 않도록 설정하는 것이 좋습니다.
인스턴스 복구 시의 동작
장애 발생 후 데이터 복구 시 Oracle은 데이터 파일에 REDO 로그를 적용하고 데이터를 최신 상태로 갱신합니다. COMMIT하지 않은 트랜잭션은 REDO 로그에도 COMMIT 정보가 존재하지 않는데 이를 통해 UNDO 정보를 사용해서 COMMIT 정보가 존재하지 않은 트랜잭션들을 구분해내어 ROLLBACK 처리를 수행함으로써 원자성을 지킵니다. UNDO가 변경되는 정보 역시 REDO 로그에 들어가 있기 때문에 롤 포워드를 통해 UNDO를 최신 상태로 만들 수 있습니다. 오라클을 기동할 때 이런 방식으로 자동 수행되는 복구를 '인스턴스 복구(instance recovery)', '충돌 복구(crash recovery)' 등으로 부릅니다.
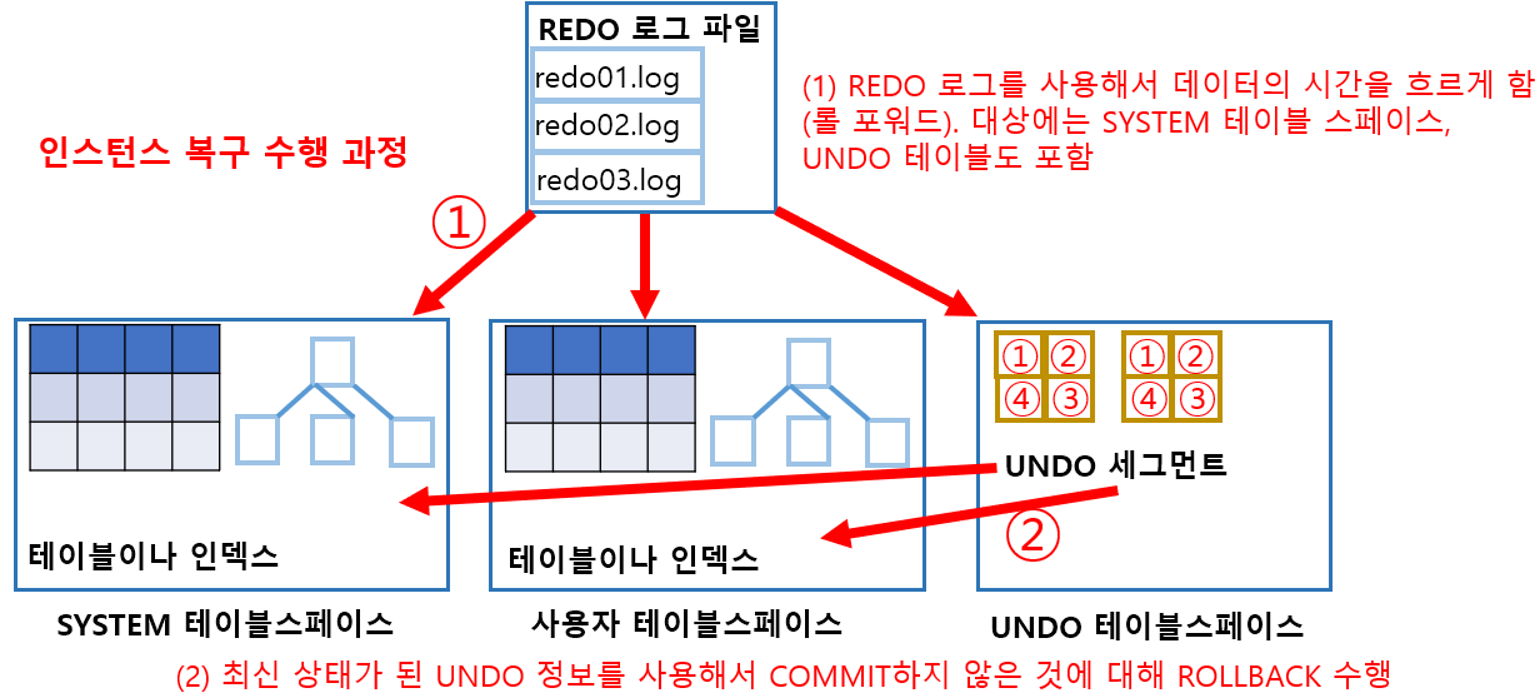
인스턴스 복구를 조금 더 빠르게 하고 싶은 경우 체크포인트가 적절한 빈도로 수행되도록 설정하는 방법이 있습니다. 또한 데이터베이스가 ABORT에 의해 정지된 후 재기동할 경우 인스턴스 복구가 수행되므로 가급적 ABORT를 사용한 정지는 피해야 합니다.
요약
- REDO는 오래된 데이터를 최신 데이터로 만들며 UNDO는 최신 데이터를 오래된 데이터로 만드는 데 사용됩니다.
- 읽기 일관성을 위해 UNDO를 사용합니다.
- ORA-01555 발생 시 undo_retention이나 테이블스페이스의 크기를 튜닝할 것을 검토하며 장시간 수행되는 SQL문으로 인해 발생한다면 애플케이션의 개선도 필요할 수 있습니다.
- 장비에 장애가 발생하거나 인스턴스 비정상 종료 시 REDO, UNDO를 사용해서 데이터를 복구하고 COMMIT하지 않은 데이터는 ROLLBACK 합니다.
참고자료
- 그림으로 공부하는 오라클 구조(스기타아츠시 외 4명)
- REDO와 UNDO 동작 과정을 이해해보자 : https://loosie.tistory.com/527